The Spiritual Alignment of dbt + Airflow

Airflow and dbt are often framed as either / or:
You either build SQL transformations using Airflow’s SQL database operators (like SnowflakeOperator), or develop them in a dbt project.
You either orchestrate dbt models in Airflow, or you deploy them using dbt Cloud.
In my experience, these are false dichotomies, that sound great as hot takes but don’t really help us do our jobs as data people.
In my days as a data consultant and now as a member of the dbt Labs Solutions Architecture team, I’ve frequently seen Airflow, dbt Core & dbt Cloud (via the official provider) blended as needed, based on the needs of a specific data pipeline, or a team’s structure and skillset.
More fundamentally, I think it’s important to call out that Airflow + dbt are spiritually aligned in purpose. They both exist to facilitate clear communication across data teams, in service of producing trustworthy data.
Let’s dive a bit deeper into that spiritual alignment, hone in on a couple cases where they play nicely, and then dive into the nitty gritty of which combination of Airflow + dbt might be right for your team.
Where Airflow + dbt align
Let’s walk through a hypothetical scenario I’d run into as a consultant, to illustrate how Airflow + dbt operate on a parallel spiritual wavelength.
TL;DR: they both provide common interfaces that data teams can use to get on the same page.
The intricacies of when I’ve found each to be useful (Airflow alone, Airflow w/ dbt Core or Cloud, dbt Core or Cloud alone) is in which team members need to get on the same page—I’ll get to that in the next section.
From the Airflow side
A client has 100 data pipelines running via a cron job in a GCP (Google Cloud Platform) virtual machine, every day at 8am.
It was simple to set up, but then the conversation started flowing:
- “Where am I going to put logs?” In a Google Cloud Storage bucket.
- “Where can I view history in a table format?” Let’s export log events into BigQuery.
- “I have to create log alerts to notify people of failures.” Let’s use GCP’s logging alerts to send emails.
- “When something fails, how do you rerun from the point of failure?” Let’s mangle the production script.
Over time, you end up building a bunch of pieces that Airflow provides out of the box.
But what makes one come alive as a data engineer—is it fine-tuning logging and making sure that the basic overhead of your pipeline works, or is it getting trustworthy data to the people you’re working with?
Airflow solves those same problems, but in a publicly-verifiable and trusted way—it provides a common interface by which data teams can get on the same page about overall data pipeline health. And that common interface is configured in code + version-controlled.
From the dbt side
That pipeline above included a plethora of data transformation jobs, built in various ways.
They were often written in naked python scripts that only ran a SQL query + wrote data to BigQuery. These stored procedure-like SQL scripts required:
- Writing boilerplate DDL (
CREATE TABLEetc * 1000) - Managing schema names between production and dev environments
- Manually managing dependencies between scripts
Again, this is pretty easy to set up, but it doesn’t get to the heart of the matter: getting trusted data to the people that you care about.
It kind of works, but you need it to really work in a way that’s publicly observable + verifiable via testing.
I have never encountered a client writing a script to auto-generate DDL, or writing boilerplate tests for SQL—no one wants these to be their job.
So like Airflow for pipeline orchestration, dbt does these things out of the box for the data transformation layer.
dbt provides a common interface where data teams can get on the same page about the business logic + run status of data transformations—again, in a way that’s configured in code + version-controlled.
If you’re curious about the migration path from a stored procedure-based transformation workflow to modular data modeling in dbt, check out my colleagues Sean McIntyre + Pat Kearns writing on migrating to an ELT pipeline.
A note on data team roles for Airflow + dbt
In my experience, these tech decisions also boil down to the data team structure you’re building around, and specifically the skills + training baked into that structure.
Tools are cheap relative to hiring + training, so I’ve most often seen tool decisions made by the availability of staff + training support, rather than the technical specs or features of the tools themselves. So let’s peek into what roles are required to build around dbt and Airflow (these same skills would also roughly map to any other orchestration tool).
Many of us define roles like data engineer, analytics engineer and data analyst differently.
So instead of getting bogged down in defining roles, let’s focus on hard skills I’ve seen in practice.

The common skills needed for implementing any flavor of dbt (Core or Cloud) are:
- SQL: ‘nuff said
- YAML: required to generate config files for writing tests on data models
- Jinja: allows you to write DRY code (using macros, for loops, if statements, etc)
YAML + Jinja can be learned pretty quickly, but SQL is the non-negotiable you’ll need to get started.
SQL skills are generally shared by data people + engineers, which makes SQL-based transformations (as in dbt) a ripe common interface for collaboration.
To layer on Airflow, you’ll need more software or infrastructure engineering-y skills to build + deploy your pipelines: Python, Docker, Bash (for using the Airflow CLI), Kubernetes, Terraform and secrets management.
How Airflow + dbt play nicely
Knowing that this toolbelt (Airflow + dbt) provides sustenance to the same spiritual needs (public observability, configuration as code, version control etc), how might one decide when and where to deploy them?
This is the same sensibility expressed in the dbt viewpoint in 2016, the closest thing to a founding blog post as exists for dbt. ]
I usually think in terms of how I want my job to look when things go wrong—am I equipped to do the debugging, and is it clear who to pass the baton to, to fix the issue (if it’s not me)?
A couple examples:
Pipeline observability for analysts
If your team’s dbt users are analysts rather than engineers, they still may need to be able to dig into the root cause of a failing dbt source freshness test.
Having your upstream extract + load jobs configured in Airflow means that analysts can pop open the Airflow UI to monitor for issues (as they would a GUI-based ETL tool), rather than opening a ticket or bugging an engineer in Slack. The Airflow UI provides the common interface that analysts need to self-serve, up to the point of action needing to be taken.

Transformation observability for engineers
When a dbt run fails within an Airflow pipeline, an engineer monitoring the overall pipeline will likely not have the business context to understand why the individual model or test failed—they were probably not the one who built it.
dbt provides common programmatic interfaces (the dbt Cloud Admin + Metadata APIs, and .json-based artifacts in the case of dbt Core) that provide the context needed for the engineer to self-serve—either by rerunning from a point of failure or reaching out to the owner.
Why I ❤️ dbt Cloud + Airflow
dbt Core is a fantastic framework for developing data transformation + testing logic. It is less fantastic as a shared interface for data analysts + engineers to collaborate on production runs of transformation jobs.
dbt Labs and the Astronomer team has been hard at work with co-developing some options for dbt Core, and a new dbt Cloud Provider for those using dbt Cloud that's ready for use by all OSS Airflow users. The best choice for you will depend on things like the resources available to your team, the complexity of your use case, and how long your implementation might need to be supported.
This tool picks up that baton, and provides a common interface where teams can configure runs + debug issues in production jobs.
If you productionalize your dbt runs in Airflow using the dbt Core operator, you run into the same SQL wrapped in Python communication challenge I mentioned at the top: the analyst who built the transformation logic is in the dark about the production run workflow, which is spiritually the thing we’re trying to avoid here.
dbt Core + Airflow
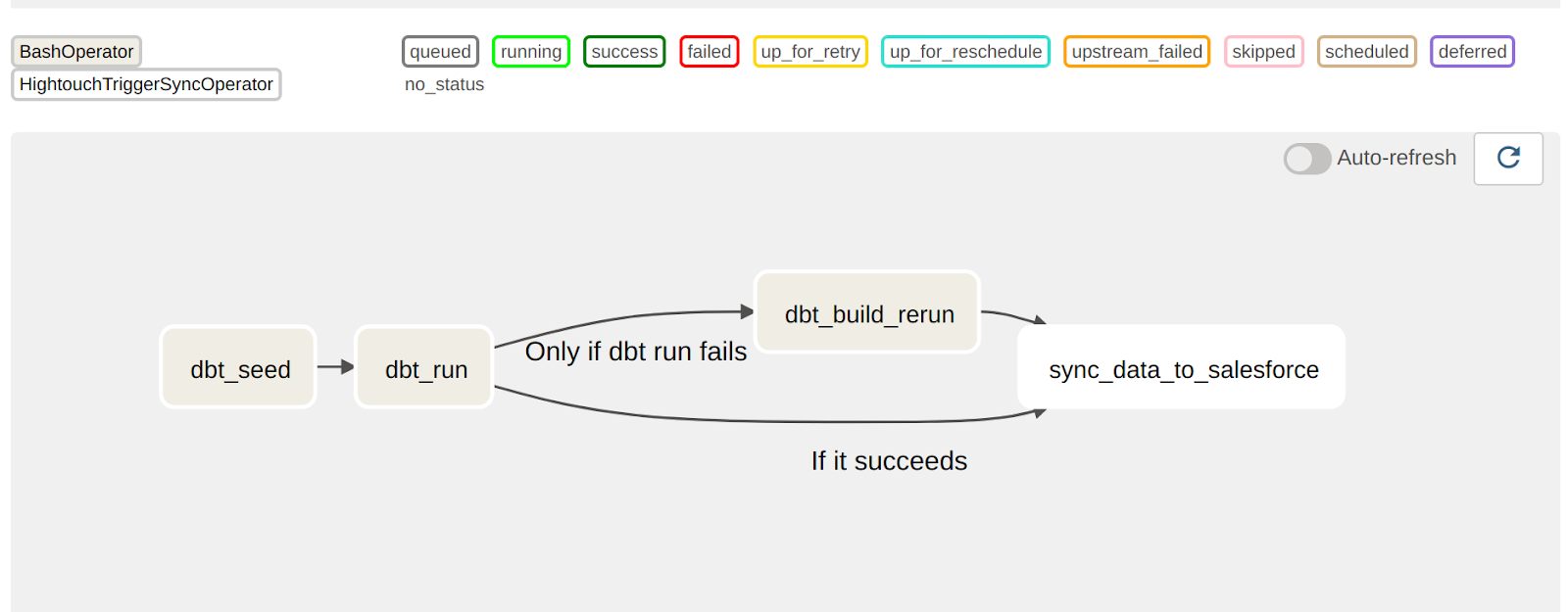
Let’s take a look at an example, from GitLab’s dbt_full_refresh Airflow pipeline.
If this task fails in the Airflow pipeline, there are a number of aspects of the pipeline to debug: was it an issue with Kubernetes or secrets, the Docker image, or the dbt transformation code itself?
An analyst will be in the dark when attempting to debug this, and will need to rely on an engineer to tap them on the shoulder in the event that the issue lies with dbt.
This can be perfectly ok, in the event your data team is structured for data engineers to exclusively own dbt modeling duties, but that’s a quite uncommon org structure pattern from what I’ve seen. And if you have easy solutions for this analyst-blindness problem, I’d love to hear them.
Once the data has been ingested, dbt Core can be used to model it for consumption. Most of the time, users choose to either: Use the dbt Core CLI+ BashOperator with Airflow (If you take this route, you can use an external secrets manager to manage credentials externally), or Use the KubernetesPodOperator for each dbt job, as data teams have at places like Gitlab and Snowflake.
Both approaches are equally valid; the right one will depend on the team and use case at hand.
| Dependency management | Overhead | Flexibility | Infrastructure Overhead | |
|---|---|---|---|---|
| dbt Core CLI + BashOperator | Medium | Low | Medium | Low |
| Kubernetes Pod Operator | Very Easy | Medium | High | Medium |
If you have DevOps resources available to you, and your team is comfortable with concepts like Kubernetes pods and containers, you can use the KubernetesPodOperator to run each job in a Docker image so that you never have to think about Python dependencies. Furthermore, you’ll create a library of images containing your dbt models that can be run on any containerized environment. However, setting up development environments, CI/CD, and managing the arrays of containers can mean a lot of overhead for some teams. Tools like the astro-cli can make this easier, but at the end of the day, there’s no getting around the need for Kubernetes resources for the Gitlab approach.
If you’re just looking to get started or just don’t want to deal with containers, using the BashOperator to call the dbt Core CLI can be a great way to begin scheduling your dbt workloads with Airflow.
It’s important to note that whichever approach you choose, this is just a first step; your actual production needs may have more requirements. If you need granularity and dependencies between your dbt models, like the team at Updater does, you may need to deconstruct the entire dbt DAG in Airflow. If you’re okay managing some extra dependencies, but want to maximize control over what abstractions you expose to your end users, you may want to use the GoCardlessProvider, which wraps the BashOperator and dbt Core CLI.
Rerunning jobs from failure
Until recently, one of the biggest drawbacks of any of the approaches above was the inability to rerun a job from the point of failure — there was no simple way to do it. As of dbt 1.0, however, dbt now supports the ability to rerun jobs from failure, which should provide a significant quality-of-life improvement.
In the past, if you ran 100 dbt models and 1 of them failed, it’d be cumbersome. You’d either have to rerun all 100 or hard-code rerunning the failed model.
One example of this is ‘dbt run –select <manually-selected-failed-model>.
Instead you can now use the following command:
dbt build –select result:error+ –defer –state <previous_state_artifacts> … and that’s it!
You can see more examples here.
This means that whether you’re actively developing or you simply want to rerun a scheduled job (because of, say, permission errors or timeouts in your database), you now have a unified approach to doing both.
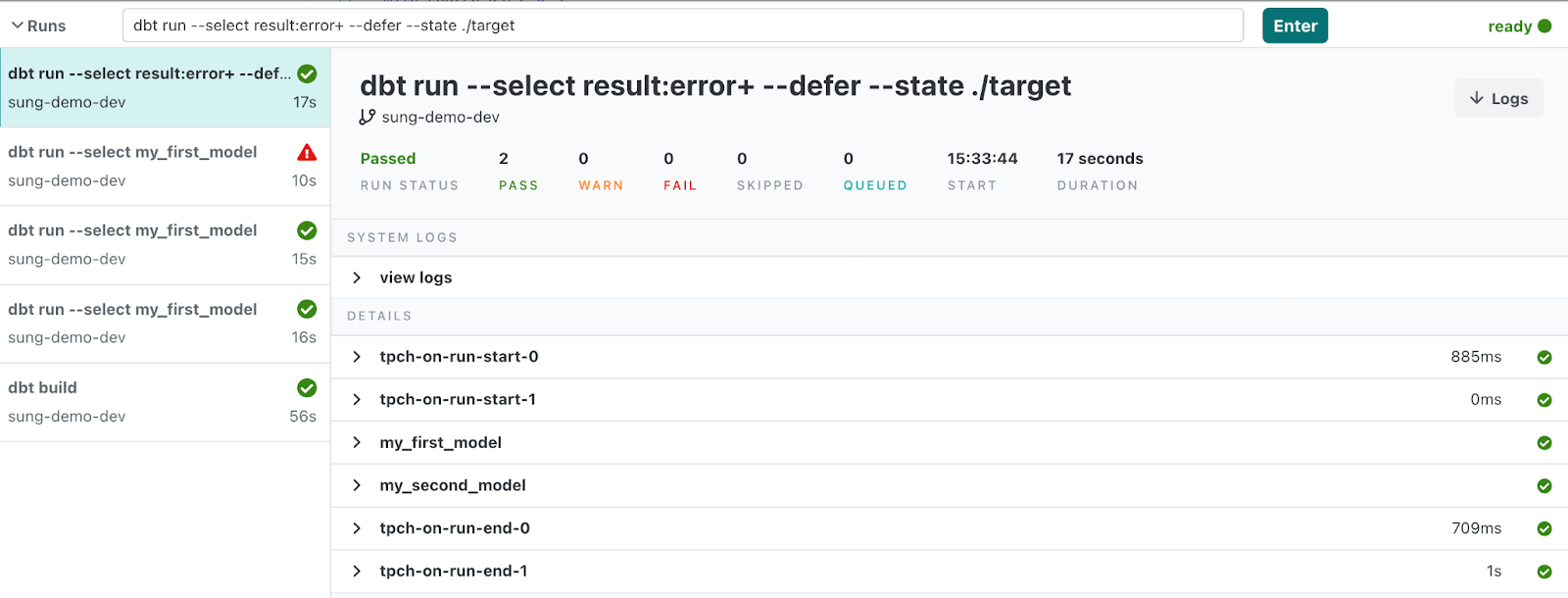
In an Airflow context, you can use this command with TriggerRules to make it so that, in the event that your initial model fails, you can keep rerunning it from the point of failure without leaving the Airflow UI. This can be especially convenient when the reason your model fails isn't related to the model code itself (permissions for certain schemas, bad data, etc.)
dbt Cloud + Airflow
Using the dbt Cloud Provider
With the new dbt Cloud Provider, you can use Airflow to orchestrate and monitor your dbt Cloud jobs without any of the overhead of dbt Core. Out of the box, the dbt Cloud provider comes with:
An operator that allows you to both run a predefined job in dbt Cloud and download an artifact from a dbt Cloud job. A hook that gives you a secure way to leverage Airflow’s connection manager to connect to dbt Cloud. The Operator leverages the hook, but you can also use the hook directly in a Taskflow function or PythonOperator if there’s custom logic you need that isn’t covered in the Operator.
A sensor that allows you to poll for a job completion. You can use this for workloads where you want to ensure your dbt job has run before continuing on with your DAG. TL;DR - This combines the end-to-end visibility of everything (from ingestion through data modeling) that you know and love in Airflow with the rich and intuitive interface of dbt Cloud.
Setting up Airflow and dbt Cloud
To set up Airflow and dbt Cloud, you can follow the step by step instructions: here
If your task errors or fails in any of the above use cases, you can view the logs within dbt Cloud (think: data engineers can trust analytics engineers to resolve errors).
This creates a much more natural baton pass, and clarity on who needs to fix what.
And if my goal is to ship trusted data, I opt for that simplicity + clarity every time.
But there are no right or wrong decisions here! Any combination of tools that solves the problem of delivering trusted data for your team is the right choice.
Comments