BigQuery ingestion-time partitioning and partition copy with dbt

At Teads, we’ve been using BigQuery (BQ) to build our analytics stack since 2017. As presented in a previous article, we have designed pipelines that use multiple roll-ups that are aggregated in data marts. Most of them revolve around time series, and therefore time-based partitioning is often the most appropriate approach.
Back then, only ingestion-time partitioning was available on BQ and only at a daily level. Other levels required to work with sharded tables. It’s still the case if we consider the partition limit set at 4096 when we’re using hourly partitions, since it translates to roughly 170 days.
We built an internal SQL query executor tool to wrap the execution of our BigQuery jobs while dbt Labs (formerly known as Fishtown Analytics) was creating its own product: dbt. After a successful experiment in 2021, dbt is now part of our go-to solution to create new BigQuery jobs at Teads. Though it misses a few custom features, it has become a superset of our former tool for everyday usage.
As column partitioning was released on BQ, and dbt favored incremental materialization, we identified one case that wasn’t well supported: ingestion-time partitioned tables using incremental materialization.
🎉 We’ve been drafting a technical solution since the end of 2021 and finally managed to merge our contribution during Coalesce 2022!
When to use ingestion-time partitioning tables
Ingestion-time partitioning tables are very similar to column-type partitioning with TIMESTAMP columns. We can actually replicate most of the behavior from each other.
Let’s see the main differences brought by ingestion-time partitioning tables:
- In ingestion-time partitioning tables, we have a
TIMESTAMPpseudo column called_PARTITIONTIME. This is not taken into account in the table’s weight which is interesting, so if you have a lot of rows, it can be worth it. You can also request_PARTITIONDATEwhich contains the same data truncated at the day-level with aDATEtype. - Selecting data from ingestion-time partitioning tables that include a pseudocolumn is also cheaper because the column is not billed. We also figured out that queries filtering on time partition columns are faster on ingestion-time partitioning tables regarding slot time. So whether we’re using “pay as we go” or “flat rate”, we’re better off with ingestion-time partitioning tables regarding performance.
- If we need to insert into multiple time partitions in a load/insert, we have to use column-type partitioning. Yet you can use a merge to insert in multiple partitions with ingestion-time partitioning tables.
- We can’t select the pseudocolumn as is for some operations such as a
GROUP BYand it must be renamed. Practically the column name is restricted and we have to alias it to something else. - We cannot use a
CREATE TABLE … AS SELECT …on ingestion-time partitioning tables; it’s one of the main reasons why dbt didn’t support them at first with incremental materialization. It requires creating the table using aPARTITION BYclause and then inserting the data.
As a rule of thumb, you can consider that if your table partition length is less than a 1 million rows, you’re better off using column-type partitioning.
How to use ingestion-time partitioning in dbt
The following requires dbt bigquery v1.4+
When we designed ingestion partitioning table support with the dbt Labs team, we focused on ease of use and how to have seamless integration with incremental materialization.
One of the great features of incremental materialization is to be able to proceed with a full refresh. We added support for that feature and, luckily, MERGE statements are working as intended for ingestion-time partitioning tables. This is also the approach used by the dbt BigQuery connector.
The complexity is hidden in the connector and it’s very intuitive to use. For example, if you have a model with the following SQL:
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date"
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
We only need to add a field to move to ingestion-time partitioning: "time_ingestion_partitioning": true
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date",
"time_ingestion_partitioning": true
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
The resulting table schema will be:
campaign_id INT64
impressions_count INT64
Indeed the day column data will be inserted into the _PARTITIONTIME pseudo column which is not visible in the table schema. Underneath, dbt generates a MERGE statement that wraps the insertion in the table. It’s very convenient when our model output contains multiple partitions and/or your incremental strategy is incremental_overwrite.
MERGE statements and performance
However, if you need to insert or overwrite a single partition, for instance, with an hourly/daily rollup, then writing on an explicit partition is much more efficient than a MERGE.
We had a job with millions of rows on which we compared both approaches and measured:
- 43 minutes with a
MERGEapproach using dbt - 26 minutes with a custom query using
WRITE_TRUNCATEon the destination table using a partition decorator
That’s a 17 minutes difference which means that almost 40% of the MERGE statement is spent on adding the data to the table.
Of course, the MERGE statement offers much more flexibility than a WRITE_TRUNCATE query. Yet in most analytics workload cases, the queries are time series that are immutable - and therefore, either the destination partition is empty or we’ll likely have to reprocess a partial period so that it translates into overwriting every row in a subset of the existing partitions.
Efficient solution
The dbt approach to insert/overwrite incremental partitions using insert_overwrite without using static partitions is the following:
- Create a temporary table using the model query
- Apply the schema change based on the
on_schema_changeconfiguration - Use a
MERGEstatement to insert the data from temporary table into the destination one
If we want to get rid of the MERGE statement, there are 2 solutions:
- Use a
SELECTstatement over the data of a partition from the temporary table and use the partition decorator on the destination table to output the data usingWRITE_TRUNCATE - Copy every partition with overwrite from using BigQuery driver
In both cases, the operation can be done on a single partition at a time so it requires a tradeoff between speed and model atomicity if multiple partitions are involved.
On a 192 GB partition here is how the different methods compare:
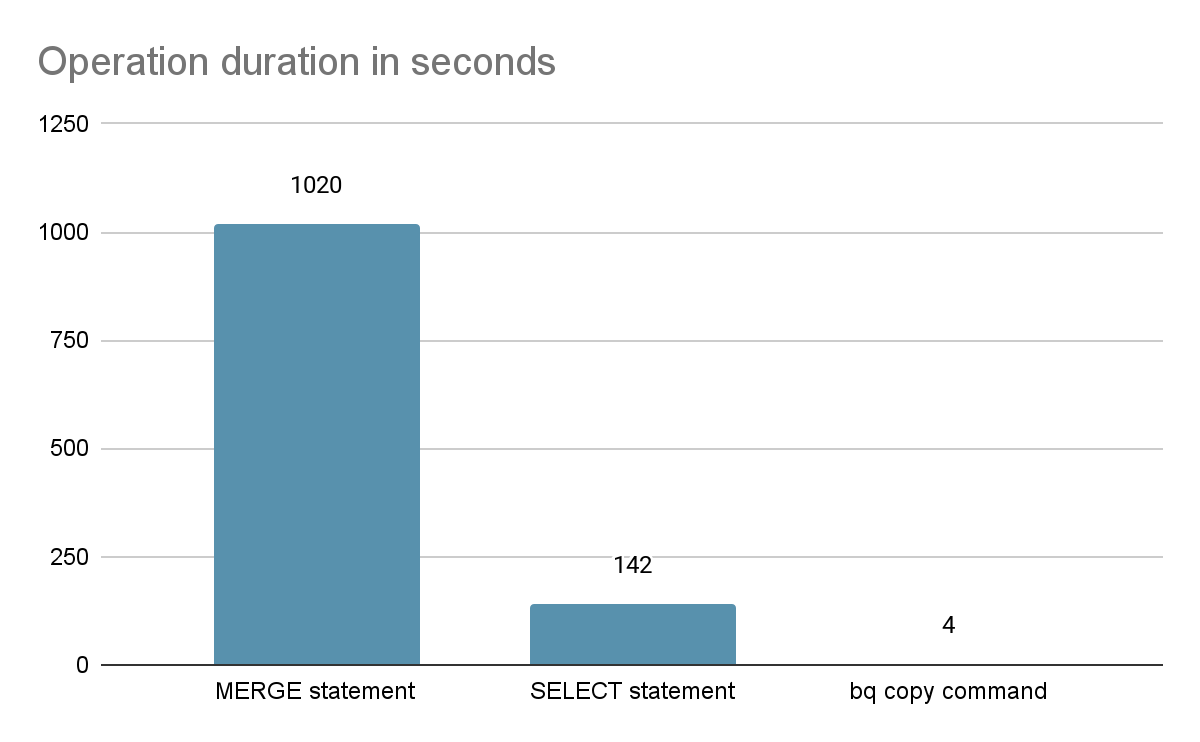
Also, the SELECT statement consumed more than 10 hours of slot time while MERGE statement took days of slot time.
So picking the BQ copy approach is definitely a no-brainer. That’s the solution we picked to improve the BQ output on incremental materialization using the insert_overwrite strategy.
Though it looks like a silver bullet, there are cases where we DON’T want to use it:
- If we have a small partition, merging on a small table, the gains are negligible
- If a lot of partitions are involved, the copy will happen sequentially. It could be parallelized in another update but depending on how many concurrent operations would be configured, the performance might still not improve enough over a
MERGEstatement. - If you need consistency across multiple partitions replacement, this approach will not fit your needs as all partitions are not replaced atomically.
How to use partition copy with dbt
The following requires dbt bigquery v1.4+
To move a model to use partition copy instead of a MERGE statement, let’s take the same model as previously:
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date"
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
Again we only need to add a field to move to partition copy: "copy_partitions": true
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
"field": "day",
"data_type": "date",
"copy_partitions": true
}
) }}
select
day,
campaign_id,
NULLIF(COUNTIF(action = 'impression'), 0) impressions_count
from {{ source('logs', 'tracking_events') }}
The configuration will be read at run time and will use the BQ driver integration to write the data using partition copy. The integration should be seamless.
Conclusion
Combining ingestion-time partitioning and partition copy is a great way to achieve better performance for your models. Of course, it would have been simpler if both features were fully integrated with SQL and didn’t require work around BigQuery Data Definition Language SQL or driver usage.
But thanks to dbt’s open-source approach and dbt Labs team, we had the opportunity to add support for those use cases and bring it to more BigQuery users.
Lastly, I wanted to share Jeremy Cohen’s post which is giving great insights to figure out how to pick an incremental strategy and its options depending on your needs.
If you love working with data at scale and look for a new challenge, have a look at our engineering job opportunities at Teads.
🎁 If this article was of interest, you might want to have a look at BQ Booster, a platform I’m building to help BigQuery users improve their day-to-day.
Comments